O czym jest ten artykuł?
Serverless zdobywa świat! Czy Serverless to dobra nazwa? Cóż, tak to ktoś wymyślił, tak się przyjęło, nikt tego już nie zmieni. Oczywiście, małą niekonsekwencją może wydawać się obecność serwerów pod maską technologii Serverless, ale, w sumie, można powiedzieć, wszystko jest kwestią perspektywy. Co jednak ważne – technologia ta daje nam, programistom, dość ciekawe możliwości, z których, między innymi, postaram się skorzystać w tym artykule.
Od razu przyznam się też do inspiracji, w tym przypadku był nią jeden z odcinków vloga „fun fun function” – kilka pomysłów z tego odcinka wykorzystałem w moich własnych eksperymentach.
Cel – najlepiej opisać go chyba jako „wycieczkę” po narzędziach i technologiach, które, albo są już dzisiaj standardem, albo po prostu, mnie osobiście, wydają się interesujące. Wszystkie narzędzia/serwisy będą wykorzystywane tylko w wersji darmowej – stąd tytułowy „free plan” – czyli bez kosztów dla nas – deweloperów, co oczywiście jest super w zastosowaniach hobbystycznych i jednocześnie (przeważnie) zupełnie nie nadaje się do zastosowań biznesowych (z czego wszyscy, mam nadzieję, zdajemy sobie świetnie sprawę).
Jako tło dla niniejszego artykułu wykorzystałem prostą aplikację Gls (mojego autorstwa), której główną funkcjonalnością jest animowanie obiektów Gls (wiem, na razie to pewnie niewiele mówi). Aplikacja posłuży mi tutaj głównie jako przykład praktycznego wykorzystania poszczególnych narzędzi.
Zapraszam do lektury!
Narzędzia
Programiści, jak wszyscy rzemieślnicy (Software craftsman) potrzebują dobrych narzędzi!
Pisząc ten artykuł wykorzystałem: GitHub, Docker Hub, Node.js, Npm, Webpack, Unpkg, OpenShift, Observable, Firebase, Heroku i Miro. Dodatkowo chciałem, ale musiałem zrezygnować ze względu na uciekający czas, skorzystać również z CircleCI, Travisa, Zeit i wypróbować CloudFlare – może następnym razem się uda.
Niestety, nie starczy tutaj miejsca na dokładniejszy opis wszystkich tych technologii, w paragrafie „Repetytorium” (nazwa trochę przewrotna) umieszczam krótką informację odnośnie tych z powyższych narzędzi, z których dokładniejszego opisu tutaj zrezygnowałem. Oczywiście, dla lektury samego artykułu, znajomość wszystkich tych technologii nie jest istotna – cel to w końcu, również, ich prezentacja (choć niekiedy bardzo krótka) czytelnikowi.
Diagram – spojrzenie na aplikację
Nic tak nie ułatwia zapoznania się z jakimś większym planem, jak spojrzenie na diagram przedstawiający jego najistotniejsze elementy. Miro jest jednym z narzędzi, które pozwalają tworzyć diagramy, czy „wirtualne tablice”, do wykorzystania w pracy zespołowej. Aby przetestować ten serwis (choć w zespole jednoosobowym) postanowiłem stworzyć, za jego pomocą, trochę schematów odnośnie aplikacji Gls (o której więcej za chwilę). Schematy te są dostępne pod adresem https://miro.com/app/board/o9J_kxlNBbU=/ (oczywiście stworzone są w ramach konta „free”). Umieściłem tam również Kanban Board realizacji Gls – jak widać, niestety nie wszystko udało się zakończyć.
Jeżeli ktoś zna/pracował z Enterprise Architect to muszę zaznaczyć, iż Miro, moim zdaniem, nie stanowi jego odpowiednika, a raczej uzupełnienie (ciekawą możliwością byłaby migracja schematów pomiędzy tymi dwoma narzędziami). To, czego brakuje mi w Miro na dzień dzisiejszy, to z pewnością możliwość tworzenia diagramów UML – Miro to bardziej narzędzie ogólnego przeznaczenia, z naciskiem na biznesowe prezentacje, niż narzędzie dedykowane programistom. Ale chyba warto obserwować ten projekt.
Aplikacja
Aplikacja Gls składa się z poniższych elementów – wszystkie zostaną omówione/wykorzystane:
• Silnik “przeliczający” obiekty Gls – biblioteka Gls
• Prezentacja obiektów Gls – aplikacja Gls-Web
• Wsparcie przy edycji obiektów Gls – Observable, tylko edycja, edycja + zapis do bazy
• Client API dostępu do bazy danych – Gls-Db-Api-Client
• API bazy danych – Gls-Db-Api
• Baza danych
Wszystkie te elementy zostały zaznaczone na poniższym schemacie:
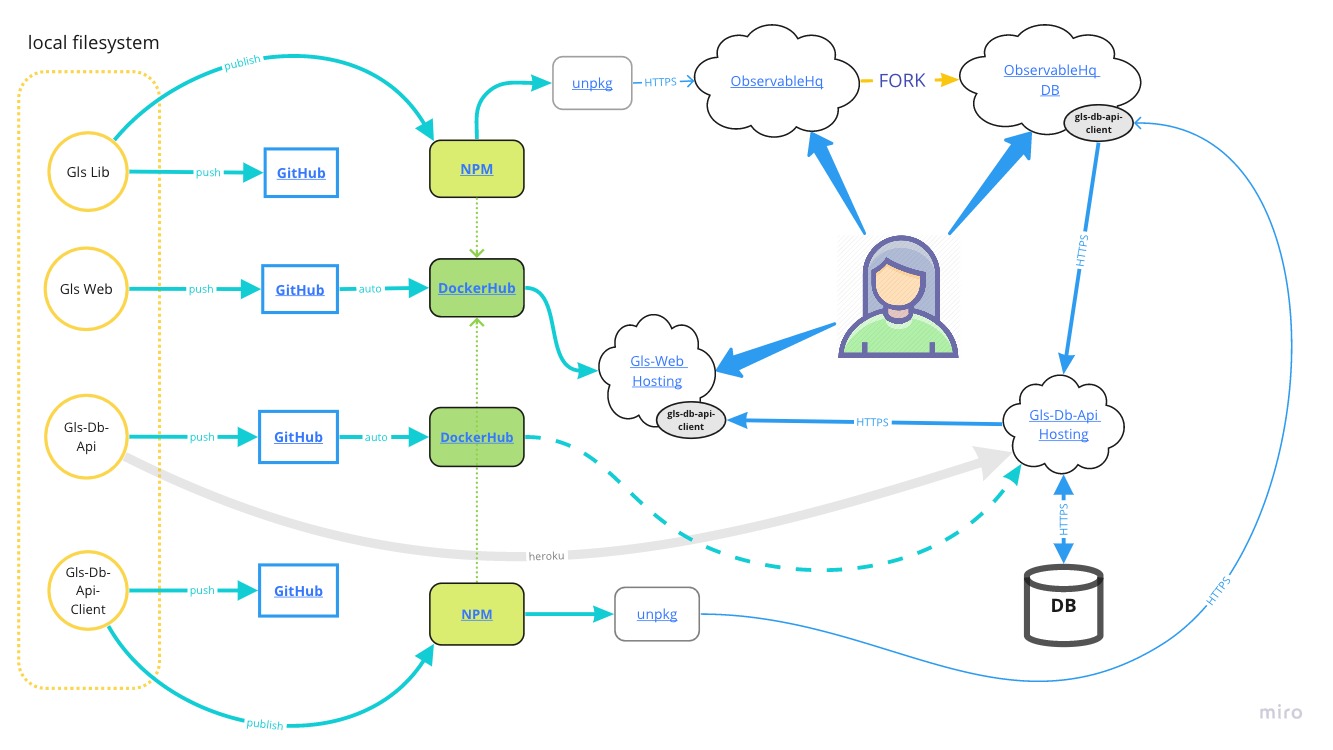
Pod tym linkiem znajduje się „interaktywna” wersja powyższego diagramu z linkami prowadzącymi do odpowiednich „elementów” aplikacji,
link ukryty pod nazwą “Gls-Web Hosting” powinien prowadzić do wersji aplikacji hostowanej na platformie OpenShift. Tutaj małe wyznanie – korzystanie z “free plan” ma oczywiście wady o których należy pamiętać – jedną z nich jest z pewnością duża „dynamika” dostępności elementów aplikacji. Oznacza to ni mniej, ni więcej, tylko tyle, że adresy url do elementów hostowanych na platformach Serverless (przynajmniej w przypadku aplikacji Gls) mają dużą tendencję do zmian – dlatego unikam w tym artykule wklejania bezpośrednich linków do aplikacji/“endpointów”, ponieważ artykuł raczej nie będzie edytowany – zamiast tego będę się starał utrzymywać w miarę aktualne linki na schemacie dostępnym poprzez Miro.
Kto odważny – niech kliknie w link z chmurki „Gls-Web Hosting”!
Funkcjonalność aplikacji nie jest tutaj najważniejsza (to nie jest artykuł o aplikacji Gls!), nie jest też celem udowodnienie słuszności zastosowanej architektury – najpewniej inni programiści rozwiązali by pewne kwestie inaczej – to tylko przykład!
Uwaga co do nazewnictwa: nazwy Gls używam w kilku kontekstach:
• Gls jako cała aplikacja – cały projekt
• Gls jako obiekt json – czyli dane do wyświetlenia / renderowania
• Gls jako biblioteka https://github.com/lbacik/gls
Zachowajcie czujność!
Repetytorium
Tak jak zaznaczałem w paragrafie „Narzędzia”, poniżej zamieszczam „kilka słów” o niektórych z wykorzystanych technologii:
Git & GitHub
Stworzony w pierwszej dekadzie tego wieku przez Linusa Torvaldsa – Git, to jeden z aktualnie najpopularniejszych rozproszonych systemów kontroli wersji. GitHub natomiast to… chyba można ten serwis nazwać jednym ze współczesnych „bazarów” (nawiązując do eseju Erica Raymonda „Katedra i Bazar” – ciekawym może wydawać się fakt, iż obecnie właścicielem serwisu GitHub jest firma Microsoft). W tym miejscu, zamiast linków do dokumentacji (myślę, że w razie potrzeby znalezienie w Internecie informacji o tych narzędziach nie będzie żadnym problemem), chciałbym polecić (tym którzy jeszcze nie oglądali) prezentację Linusa, dotyczącą Git-a, wygłoszoną w siedzibie Google 12 lat temu: https://www.youtube.com/watch?v=4XpnKHJAok8.
Kontenery, Docker & Docker Hub
Docker nie jest jedynym, aktualnie dostępnym, wysokopoziomowym narzędziem do zarządzania Linuksowymi Przestrzeniami Nazw (Linux Namespaces) – ale chyba przyjął się najlepiej! W końcu ilu deweloperów zna Lxc/Lxd czy Rkt? Ponieważ wszystkie te narzędzia są mimo wszystko dość podobne (wszystkie wykorzystują ten sam mechanizm, którym są Linuksowe Przestrzenie Nazw (Linux Namespaces), to trochę może dziwić tak duża dysproporcja w ich rozpoznawalności wśród programistów (i nie tylko). Co więc stoi za tak dużym sukcesem Dockera? Każdy może mieć oczywiście swoją teorię, ja stawiałbym na serwis Docker Hub – moim zdaniem, globalne repozytorium „dockerowych” obrazów (docker images), to był przysłowiowy strzał w dziesiątkę!
Do aplikacji Gls-Web dodany został plik Dockerfile. To pozwala zbudować każdemu kontener lokalnie. Taki „obraz”, w przypadku własnych projektów, można wysłać do repozytorium Docker Hub, aby udostępnić go innym użytkownikom. Jednak, jeżeli eksport nie jest jednorazowy i chcemy utrzymywać synchronizację pomiędzy projektem w serwisie GitHub a obrazem w serwisie Docker Hub to lepszym rozwiązaniem będą aktualizacje automatyczne. W tym celu, dla projektu na Docker Hub, możemy wybrać integrację z GitHub (do wyboru jeszcze Bitbucket), a następnie ustawić „wyzwalacz” (trigger) na wskazany branch w repozytorium Git. Oznacza to, że po wprowadzeniu zmian do tego, wybranego brancha, Docker Hub automatycznie rozpocznie budowanie kontenera wg pliku Dockerfile w repozytorium. Tak skonfigurowałem to właśnie w przypadku Gls-Web i Gls-Db-Api – obrazy Gls-Web i Gls-Db-Api są budowane automatycznie po każdej zmianie w projektach (branch master) Gls-Web i Gls-Db-Api!
Więcej informacji w dokumentacji na docker.com, oraz w pliku README.md projektu Gls-Web.
Node.js, Npm, Webpack & Unpkg
Aplikacja Gls została napisana w JavaScript, z wykorzystaniem Node.js.
Node.js to „środowisko uruchomieniowe” dla języka JavaScript, które powstało z myślą o wykorzystaniu JS w tzw. backendzie. Termin „środowisko” okazuje się mieć tutaj znaczenie, co w świetny sposób tłumaczy Philip Roberts w prezentacji: What the heck is the event loop anyway?, opisującej sposób działania JS w przeglądarce jak i w implementacji Node.js.
Npm to manager pakietów dla Node.js – jednak, nie tylko. Pozwala on również na publikowanie własnych bibliotek w centralnym repozytorium (tak, aby inni programiści mogli je pobrać i wykorzystać w swoich projektach).
Aby umożliwić korzystanie z biblioteki Gls (i Gls-Db-Api-Client) w środowisku JS przeglądarki skorzystałem natomiast z Webpack i Unpkg – poniżej wyjaśnię ich rolę, to w sumie ciekawa kwestia świata JS.
Gls-Web wykorzystuje bibliotekę Gls w dość specyficzny sposób. Gdy kod biblioteki Gls na zostać dołączony do dokumentu HTML wysyłanego do przeglądarki, “backend” korzysta z metody code, klasy Generator, której rezultatem jest zwrócenie (w postaci ciągu znaków) całego kodu biblioteki Gls potrzebnego do renderowania obiektów Gls w przeglądarce (kod ten możemy znaleźć w źródle dokumentu HTML).
1. To dość toporna metoda.
2. Z metody takiej nie możemy skorzystać w aplikacjach typu Observable (o Observable napiszę w jednym z kolejnych paragrafów) ponieważ nie mamy dostępu do kodu działającego w backendzie.
Punkt pierwszy możemy rozwiązać/poprawić przygotowując wersję naszej biblioteki w formacie UMD. Aby rozwiązać problem z pkt 2 możemy udostępnić przygotowaną wersję UMD poprzez serwis typu Unpkg.
Weźmy bibliotekę Gls – jeżeli chcielibyśmy „wczytać” ją z poziomu przeglądarki, wykorzystując np. link https://unpkg.com/@lbacik/gls (Unpkg zaserwuje nam w takim przypadku plik wskazany w package.json jako „main” – czyli naszą fabrykę to tworzenia obiektów Gls), to niestety to nie zadziała – runtime JS uruchomiony w przeglądarce nie będzie wiedział jak interpretować polecenia „require” – czyli jak dołączyć pozostałe pliki pakietu…
Tutaj na scenę wchodzi UMD – specyfikacja ta pozwoli nam przygotować odpowidnią wersję biblioteki Gls. Oczywiście nie chodzi o przepisanie biblioteki od zera, a wykorzystanie jednego z narzędzi, które skonwertuje naszą bibliotekę (przygotowaną dla Node.js) do odpowiedniego formatu (umożliwiającego jej wykorzystanie w środowisku przeglądarki) – ja zdecydowałem się na wykorzystanie do tego celu właśnie narzędzia Webpack. W katalogu głównym biblioteki Gls umieściłem plik konfiguracyjny webpack.config.js, oraz przygotowałem „skrót” do wywołania webpacka w `package.json`, sama biblioteka natomiast wskazana jest w zależnościach środowiska developerskiego aplikacji.
Wywołując przygotowany skrót:
$ npm run build
generowana jest wersja pakietu w formacie UMD. Ta wersja zostaje zapisana w katalogu `dist`. Sam katalog `dist` wyłączony jest z zapisu w repozytorium git (plik .gitignore), ale włączony jest do uploadu do repozytorium npmjs.com (plik package.json, klucz „files”). Czyli, po opublikowaniu pakietu na npmjs.com, wersja pakietu Gls przygotowana przez narzędzie Webpack będzie dostępna, poprzez serwis Unpkg, pod adresem url: https://unpkg.com/@lbacik/gls/dist/gls.js
I to jest to! Skorzystamy z tej wersji pakietu Gls (jak i również analogicznie przygotowanej wersji pakietu Gls-Db-Api-Client) w aplikacji Observable. Oczywiście w profesjonalnych aplikacjach takie „dystrybucyjne” wersje powinny być jeszcze minimalizowane, aby ograniczyć ich rozmiar, ale ja już odpuściłem ten krok (przynajmniej w aktualnej wersji aplikacji Gls).
Serverless – starcie pierwsze
Czas na pierwsze starcie z Serverless! Docker Hub to bardzo przydatne narzędzie – jednak, dany kontener, musimy pobrać i uruchomić lokalnie (bądź też, mówiąc bardziej ogólnie – w ramach swojej infrastruktury). To nie sprawi problemu osobom zaznajomionym z tą technologią, jednak większość potencjalnych użytkowników wolałaby chyba po prostu dostać adres url, który mogliby „kliknąć” i cieszyć się aplikacją. Czy udostępnienie takiego, globalnego adresu url, bez opłacenia dostępu do jakiejś platformy hostingowej, serwera VPS czy tego typu rzeczy, jest możliwe? Okazuje się, że aktualnie, w tej kwestii „nie jest źle”, a z pewnością, w przyszłości, będzie coraz lepiej!
W pierwszym starciu sięgnąłem po sprawdzone (w moim przypadku) już rozwiązanie – openshift.com.
OpenShift to platforma rozwijana przez Red Hat i zbudowana z wykorzystaniem technologi od Google (przynajmniej pierwotnie) – Kubernetes. W planie „free”, mamy do dyspozycji 4 pody (każdy z 0.5 GB Ram) – to naprawdę nieźle! W trakcie konfiguracji projektu możemy wskazać dockerowy image dostępny np. w serwisie Docker Hub, image ten zostanie pobrany i uruchomiony w jednym z podów, domyślnie, bez możliwości dostania się do aplikacji z Internetu, ale jednym/dwoma kliknięciami, bez problemu, zdefiniujemy odpowiedni routing. Po aktualny adres aplikacji Gls-Web hostowanej na OpenShift odsyłam do schematu na Miro – chodzi mi tutaj o link opisany na diagramie jako „Gls-Web Hosting” – adres, który ukrywa się pod tym linkiem, będzie raczej trudny do zapamiętania, ale na testy/demo w zupełności wystarczy.
Tak więc, użytkownik nie musi pobierać kodów źródłowych z GitHub (i budować aplikacji lokalnie), czy kontenera z Docker Hub – możemy przygotować również opcję z dostępem po url!
Observable
Gls-Web pozwala przeglądać przygotowane wcześniej obiekty Gls. Brakuje jednak jakiegoś „edytora” tych obiektów – narzędzia, które można by wykorzystać przy ich tworzeniu.
Obiekty Gls to obiekty typu json, kilka przykładów można znaleźć w katalogu examples projektu Gls-Web (przykłady z tego katalogu są wyświetlane w podstawowym trybie pracy aplikacji Gls-Web, są to przykłady z zakładki „local” – bądź też jedyne widoczne przykłady, jeżeli url do bazy danych nie został przekazany do Gls-Web).
Oczywiście, można rozbudować aplikację Gls-Web o jakiś prosty edytor plików Gls, ale… zróbmy użytek z naszej dekompozycji i spróbujmy poeksperymentować z Observable!
Ogólnie Observable można chyba nazwać narzędziem do zabaw z JavaScriptem. Dostarcza ono nam dość szczególnego środowiska pracy dla naszych skryptów – pozwalającego na przygotowanie interakcji w (jak dla mnie) dość nowatorki sposób. Dysponujemy notatnikiem w którym możemy osadzać skrypty i elementy HTML – skrypty oczywiście mogą wymieniać między sobą dane, kontrolować różne osadzone elementy, takie jak suwaki, czy renderować grafikę. Wszystkie zmiany w notatniku są śledzone, mamy możliwość „forkowania” notatników innych użytkowników i modyfikowania ich na własny użytek… ciekawe?
Pierwszy notatnik który przygotowałem: https://observablehq.com/@lbacik/untitled (za nic nie udało mi się przemianować tego „untitled” na „gls” – bug?)
Nie jest on zbyt skomplikowany – zawiera trzy elementy:
1. obiekt GLS (a raczej obiekt Canvas na którym renderowany jest obiekt Gls)
2. import fabryki GLSFactory z biblioteki Gls – w formie modułu UMD i z wykorzystaniem Unpkg
3. animation loop – potrzebne aby wszystko ładnie działało
Elementy notatnika możemy podglądać i edytować po wybraniu opcji „edit” z menu kontekstowego elementu, dostępnego po najechaniu na „trzy kropki”, które pojawiają się gdy kursor przesuniemy blisko lewej strony elementu).
Podglądając np. drugi element:
GlsFactory = class
Powinniśmy zobaczyć następujący kod:
GlsFactory = require('https://unpkg.com/@lbacik/gls/dist/gls.js')
Wygląda znajomo?
Observable automatycznie wykonuje kod, który umieszczamy w notatniku, tak więc nasz notatnik staje się… aplikacją. Jeżeli teraz otworzymy pierwszy z elementów i zaczniemy modyfikować kod naszego obiektu Gls (json) to efekt zobaczymy od razu po „przesłaniu/wgraniu” zmian (symbol “strzałki”, jak na klawiszu play w odtwarzaczach, widoczny w prawym-górnym rogu edytowanego elementu notatnika).
Problem, którego na razie nie udało mi się rozwiązać w zadowalający sposób to sposób prezentacji – czegoś tutaj jeszcze brakuje, czegoś dzięki czemu można by było bardziej „swobodnie” zarządzać położeniem elementów notatnika, choć, nawet bez tego, myślę, że jest świetnie!
Powrócę jeszcze do tego serwisu w jednym z kolejnych paragrafów.
Baza Danych
Baza danych przyda się, abyśmy nie musieli publikować nowej wersji Gls-Web za każdym razem, gdy chcemy pochwalić się nowym obiektem Gls (które to obiekty aktualnie są „przechowywane” jedynie jako pliki json w katalogu examples projektu Gls-Web). Dzięki wykorzystaniu bazy zyskamy centralne repozytorium dla naszych plików json!
Po bazę, (śladami MPJ), udałem się do Googla – mamy tutaj interesującą opcję NoSQL – Firebase!
Aktualnie możemy korzystać z dwóch „wersji” usługi firebase
1. Realtime Database – kto nie słyszał, niech się nie martwi, bo ta wersja określona jest już jako „przestarzała”
2. Cloud Firestore – nowa odsłona
Dla mnie przy wyborze najważniejsze były limity przy planie free i tutaj (jakżeby inaczej) – Realtime Database, jako technologia „przestarzała”, daje poszaleć znacznie bardziej. Tak więc wybór padł właśnie na tę wersję!
Realtime Database to tak naprawdę… plik json! Choć w rzeczywistości to nie jest aż tak proste, bo możemy definiować zasady dostępu do poszczególnych elementów (węzłów) naszego pliku (naszych danych), metody uwierzytelnienia czy walidację – ogólnie można wykazać się inwencją, ja jednak ograniczę się do minimum (choć opcja walidacji przesyłanych danych jest kusząca i może do niej wrócę w przyszłości).
Polecam założyć konto i wypróbować usługę – interfejs jest bardzo przystępny i obsługa bazy nie powinna sprawiać dużych kłopotów.
Ponieważ dostęp bezpośredni może być trochę kłopotliwy dla klientów (Gls-Web i Observable) i w sumie powodował by duplikację kodu, dlatego realizowany będzie przez API (Gls-Db-Api). Dodam również klienta (Gls-Db-Api-Client), aby miało to bardziej „zwięzłą” formę, i aby dany serwis mógł praktycznie od razu wywoływać metody pobierające bądź przesyłające dane do bazy.
Serverless – starcie drugie
I kolejne starcie z Serverless – tym razem sięgnijmy po Heroku (oczywiście wybieram plan free) – po sklonowaniu źródeł Gls-Db-Api, Api może zostać udostępnione za pomocą poleceń (informacje w dokumentacji: https://devcenter.heroku.com/articles/container-registry-and-runtime):
$ heroku container:login
$ heroku create
$ heroku container:push web
$ heroku container:release web
W przypadku kontenera wrzuconego przeze mnie adres został wpisany do schematu aplikacji w Miro – link do api kryje się w „chmurce” „Gls-Db-Api Hosting”.
Akcje takie jak `list` i `get` powinny być dostępne z poziomu przeglądarki (wykorzystują metodę GET protokołu HTTP):
• https://API-URL/list – zwróci tablicę elementów Gls w bazie (format json)
• https://API-URL/get/gls01 – zwróci konkretny obiekt json z bazy – w tym przypadku: 'gls01′
Oczywiście są różnice w stosunku do OpenShift – nie korzystamy tutaj z kontenera pobieranego ze zdalnego repozytorium (Docker Hub), tutaj budujemy taki kontener lokalnie (w swoim lokalnym systemie) a następnie wysyłamy go do serwisu heroku. Aby móc tę operację przeprowadzić musimy zainstalować klienta cli serwisu heroku. Ponadto, w odróżnieniu od OpenShift, nasza aplikacja domyślnie dostępna jest poprzez połączenie szyfrowane (https) – w przypadku OpenShift musielibyśmy sami wygenerować certyfikat i dodać go w konfiguracji routingu – nie jest to wielka filozofia, ale zawsze kilka rzeczy dodatkowych do zrobienia. Co jednak tutaj istotne, w przypadku Gls-Web, ssl nie jest dla nas specjalnie istotny, natomiast w przypadku Gls-Db-Api, w związku z danymi użytkownika wymaganymi przez akcję „add”, szyfrowanie jest już wskazane! Dodatkowo, wykorzystanie protokołu https w komunikacji ze zdalnymi serwisami jest wymagane przez serwis Observable (Observable będzie się łączyć z Gls-Db-Api wykorzystując Gls-Db-Api-Client) – połączenia korzystające z protokołu http są blokowane!
Observable DB
Wersja notatnika korzystająca z bazy to fork notatnika opisanego w poprzednim paragrafie o Observable – dodałem jedynie formatkę, służącą do wysyłania (za pomocą Gls-Db-Api-Client) edytowanego obiektu Gls do bazy. Przydałoby się tutaj jeszcze trochę pracy – nie działa to idealnie, ale dane są przesyłane i zapisywane, więc jest ok przynajmniej z technicznego punktu widzenia!
Oczywiście możliwość zapisu jest zabezpieczona hasłem, więc aby przeprowadzić własny test trzeba skonfigurować bazę i wystawić gdzieś endpoint API – ważne, aby komunikacja była po https (pal licho hasła, ale observable po prostu będzie blokował komunikację nieszyfrowaną).
Ostatnia rzecz to kwestia CORS – kod definiujący połączenie do API wygląda następująco (element poniżej formularza):
const dbapi = GlsApiClient.create('https://cors-anywhere.herokuapp.com/' + dbUrl)
Usługa https://cors-anywhere.herokuapp.com rozwiązuje problem przy małym natężeniu ruchu, więcej informacji jest w tym notatniku – również jak skonfigurować whitelistę po stronie heroku.
Podsumowanie
I w sumie to już koniec tej „wycieczki” – aplikacja Gls działa i jest dostępna (wczytywanie obiektów z bazy niekiedy trwa trochę długo, ale cóż – to są minusy, z którymi należy się liczyć w tego typu implementacjach).
Niestety nie udało mi się tutaj poruszyć wszystkich tematów, które wynotowałem sobie w pierwszym szkicu tego artykułu. Tak jak wspominałem już na początku, takie rzeczy jak CI/CD czy Load Balancing musiałem porzucić (zgodnie ze „zwinną” wersją „żelaznego trójkąta”). To oznacza, że eksperyment można kontynuować i rozszerzać jego funkcjonalność – zachęcam do tego w wolnych chwilach (w ramach swoich własnych mini-projektów, bądź w ramach Gls!). W końcu „praktyka” to podstawa, a jak się okazuje, aby podnosić nasze devopsowe umiejętności, wcale nie musimy dysponować dostępem do (jakiejkolwiek) serwerowni – wystarczy dostęp do Internetu!
Autorem tekstu jest Łukasz Bacik.