Zacznę może od genezy problemu. Pracowałem nad optymalizacją zużycia pamięci w pewnym procesie importu danych, ponieważ pierwsze analizy wskazywały na użycie około 890MB – taka wartość była nie do przyjęcia. Standardowo na pierwszy ogień poszły obiekty DAO na rzecz zwykłych tablic – efektem był spadek do 280MB. Niemniej to nadal zbyt dużo, celem było maksimum 128MB. Analizując cały proces doszedłem do wniosku, że można przyspieszyć trochę proces i pozbyć się sporej ilości pamięci usuwając standardowe wyszukiwanie wierszy przez repozytorium obiektów DAO w zamian budując mini-repozytorim składające się z tablicy par (czyli tablica tablic de facto) [id, source_id]. Pierwsze testy i spore zaskoczenie, bo tak prosta struktura składająca się z około 65000 par zajmowała około 27MB. Poniżej przykład:
<?php
echo number_format(memory_get_usage(), 0, '.', ' ') . "\n";
$a=[];
for ($i=0; $i<65536; $i++)
{
$a[] = [$i, 2*$i];
}
echo number_format(memory_get_usage(), 0, '.', ' ') . "\n";
echo number_format(memory_get_peak_usage(), 0, '.', ' ') . "\n";
daje w rezultacie:
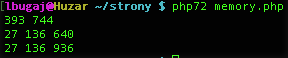
Jest to wartością dość dużą, niestety. Zrobiłem szybko jeszcze dwa inne testy. Tablica jednowymiarowa z narzuconym indeksem:
<?php
echo number_format(memory_get_usage(), 0, '.', ' ') . "\n";
$a=[];
for ($i=0; $i<65536; $i++)
{
$a[2*$i] = $i;
}
echo number_format(memory_get_usage(), 0, '.', ' ') . "\n";
echo number_format(memory_get_peak_usage(), 0, '.', ' ') . "\n";
dało w rezultacie:

oraz tablica jednowymiarowa bez narzuconego indeksu:
<?php
echo number_format(memory_get_usage(), 0, '.', ' ') . "\n";
$a=[];
for ($i=0; $i<65536; $i++)
{
$a[] = $i;
}
echo number_format(memory_get_usage(), 0, '.', ' ') . "\n";
echo number_format(memory_get_peak_usage(), 0, '.', ' ') . "\n";
co dało wynik:
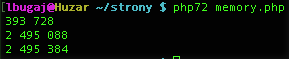
Różnica między drugim i trzecim testem choć znaczna, to i tak jest niewielka w porównaniu do pierwszego testu – zużycie pamięci jest prawie 10 razy mniejsze. Zacząłem się zastanawiać, co takiego tkwi wewnątrz tablic w PHP, że prosta struktura z niewielką ilością danych pochłania kosmiczne ilości pamięci?
Ściągnąłem więc źródła PHP w wersji 7.2.14 i po poszukiwaniach znalazłem powód.
Uwaga! Wszystkie wyliczenia prowadzone są z założeniem kompilacji kodu dla 64-bitowego procesora i systemu operacyjnego: typ long ma 8 bajtów, wskaźniki mają 8 bajtów.
Najpierw należy wyjaśnić, jak PHP wewnętrznie przechowuje zmienne. Zmienne w PHP z definicji nie mają typu, można string traktować jak integer i na odwrót (od PHP 7 mamy TypeHint, ale to jest inny mechanizm). Skąd więc wiadomo jakiego typu jest zmienna? Wewnętrznie odpowiada za to struktura ZVAL (zend_value) i wygląda ona tak:
struct _zval_struct {
zend_value value; /* value */
union {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar type, /* active type */
zend_uchar type_flags,
zend_uchar const_flags,
zend_uchar reserved) /* call info for EX(This) */
} v;
uint32_t type_info;
} u1;
union {
uint32_t next; /* hash collision chain */
uint32_t cache_slot; /* literal cache slot */
uint32_t lineno; /* line number (for ast nodes) */
uint32_t num_args; /* arguments number for EX(This) */
uint32_t fe_pos; /* foreach position */
uint32_t fe_iter_idx; /* foreach iterator index */
uint32_t access_flags; /* class constant access flags */
uint32_t property_guard; /* single property guard */
uint32_t extra; /* not further specified */
} u2;
};
typedef union _zend_value {
zend_long lval; /* long value */
double dval; /* double value */
zend_refcounted *counted;
zend_string *str;
zend_array *arr;
zend_object *obj;
zend_resource *res;
zend_reference *ref;
zend_ast_ref *ast;
zval *zv;
void *ptr;
zend_class_entry *ce;
zend_function *func;
struct {
uint32_t w1;
uint32_t w2;
} ww;
} zend_value;
Nie będę dalej rozwijał wszystkich typów, tym bardziej że z ich nazwy można się zorientować, co tam jest. Generalnie struktura zend_value zawiera trzy pola, z których każde jest unią i ma długość:
• value – 8 bajtów
• u1 – 4 bajty
• u2 – 4 bajty
Wynika z tego, że sama struktura opisująca zmienną ma wielkość przynajmniej 16 bajtów, nie licząc wartości samej zmiennej: dla typów całkowitych i zmiennoprzecinkowych będzie to 0 (zero), ponieważ mieszczą się one bezpośrednio w strukturze; dla łańcuchów, tablic, obiektów itp. jest to tyle, ile wynosi rozmiar tej zmiennej – w strukturze jest przechowywany tylko wskaźnik do pamięci zajmowanej przez zmienną.
W naszym przykładzie było około 65000 liczb całkowitych, co daje 1,0MB na same liczby.
No dobrze, ale co w końcu z tymi tablicami? Tablice są opisane inną strukturą, zend_array:
struct _zend_array {
zend_refcounted_h gc;
union {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar flags,
zend_uchar nApplyCount,
zend_uchar nIteratorsCount,
zend_uchar consistency)
} v;
uint32_t flags;
} u;
uint32_t nTableMask;
Bucket *arData;
uint32_t nNumUsed;
uint32_t nNumOfElements;
uint32_t nTableSize;
uint32_t nInternalPointer;
zend_long nNextFreeElement;
dtor_func_t pDestructor;
};
typedef struct _Bucket {
zval val;
zend_ulong h; /* hash value (or numeric index) */
zend_string *key; /* string key or NULL for numerics */
} Bucket;
typedef struct _zend_refcounted_h {
uint32_t refcount; /* reference counter 32-bit */
union {
struct {
ZEND_ENDIAN_LOHI_3(
zend_uchar type,
zend_uchar flags, /* used for strings & objects */
uint16_t gc_info) /* keeps GC root number (or 0) and color */
} v;
uint32_t type_info;
} u;
} zend_refcounted_h;
No i tablica okazała się całkiem rozbudowanym tworem. Mamy strukturę zend_refcounted_h z której korzysta GarbageCollector, mamy strukturę Bucket w której są poszczególne elementy tablicy no i w końcu strukturę samej tablicy, gdzie mamy rozmiar, wskaźnik bieżącego elementu itd.
Rozmiary poszczególnych części przedstawiają się następująco:
• zend_refcounted_h – 8 bajtów
• Bucket – 32 bajty (16 bajtów zval plus 2 pola po 8 bajtów)
• zend_array – 56 bajtów (nie będę się tutaj rozpisywał, kto jest chętny może sobie sprawdzić)
Podsumowując: nasza tablica 65536 elementów typu całkowitego (integer) ma rozmiar:
• struktura zend_array: 56 bajtów
• 65536 elementów Bucket zawierających wartości integer: 2 097 120 bajtów
Razem daje to 2 097 176 bajtów, co jest w miarę zgodne z tym, co widzieliśmy w trzecim teście. Jak w takim razie wyglądałyby obliczenia dla pierwszego testu?
• struktura zend_array: 56 bajtów
• 65536 elementów Bucket zawierających tablicę: 2 097 120 bajtów
◦ struktura zend_array: 65536 * 56 bajtów = 3 670 016 bajtów
◦ 2 elementy Bucket zawierające liczby całkowite: 65536 * 2 * 32 bajty = 4 194 304 bajty
Łącznie daje to 9 961 496 bajtów. 10MB pamięci na dane, które w języku C zajęłyby maksymalnie 1MB to dość szokujące odkrycie. Tym bardziej, że podliczyłem same struktury danych, bez uwzględnienia faktu wyrównywania pól w strukturach do granicy 8 bajtów (biorąc to pod uwagę np. struktura zval_struct będzie zajmować w pamięci 24 bajty, nie 16; zend_array 80 bajtów zamiast 56) oraz samego zarządzania pamięcią w PHP, struktur pomocniczych itp.
W porządku, a co z obiektami? Cóż, są równie rozbudowane jak tablice:
struct _zend_object {
zend_refcounted_h gc;
uint32_t handle; // TODO: may be removed ???
zend_class_entry *ce;
const zend_object_handlers *handlers;
HashTable *properties;
zval properties_table[1];
};
HashTable to alias dla zend_array (lepiej wygląda….), reszta jest wskaźnikami lub definicje są przedstawione wyżej, suma rozmiaru wszystkich pól daje 52 bajty (72 bajty uwzględniając memory alignment).
Cóż… Mit tak uwielbianych przeze mnie tablic legł w gruzach, tablice nie są dobre na wszystko i okazuje się, że bardzo łatwo jest naciąć się przy ich używaniu. Natomiast mając na względzie, jak są reprezentowane wewnętrznie w PHP można je efektywnie wykorzystywać – tablica składająca się z tablic o dużej liczbie elementów będących typami prostymi jest nadal jednym z najbardziej efektywnych sposobów przechowywania danych. Przypadek tablicy składającej się z dwu-elementowych tablic daje się na szczęście w prosty sposób zredukować do tablicy jednowymiarowej (indeks to jeden element, wartość to drugi).
Na zakończenie powiem jeszcze, że stosując kilka innych sztuczek (przetwarzanie w małych paczkach, korzystanie niemal wyłącznie z PDO, mini-repozytorium par danych) udało mi się zredukować zużycie pamięci z początkowego 890MB do 20MB; szybkość „przy okazji” też wzrosła z około 10 do 2 minut.
Autorem tekstu jest Łukasz Bugaj.